Article 1. 데이터 수집 1311
Section 1. 데이터 수집 및 전환
Paragraph 1. 데이터 수집 프로세스
수집 대상 데이터 목록을 선정하고 수집을 위한 세부 수집계획을 작성한 후 데이터를 수집한다.
-
수집 데이터 도출
- 수집 데이터 도출은 빅데이터 서비스 제공 시 서비스 품질을 결정하는 중요한 핵심 업무
- 데이터 도메인의 분석 노하우가 있는 내 외부 전문가 의견을 수렴하여 분석 목적에 맞는 데이터 도출 필요
-
목록 작성
- 수집 가능성 여부, 보안 문제, 세부 데이터 항목(품질) 및 비용 등을 검토하여 데이터 수집 목록 작성
-
가능성
해당 데이터가 사용 가능하고 수집 가능한가?
-
보안
수집 시 개인정보 포함 여부 및 유출 문제는 없는가?
-
정확성
활용 목적에 따른 세부 항목들이 적절히 포함되었는가?
-
수집 비용
데이터 수집에 드는 비용은 얼마인가
-
데이터 소유기관 파악 및 협의
- 데이터 소유자의 데이터 개발 현황/조건, 적용기술, 보안 사항 등을 파악하고 필요한 협의 진행
- 데이터 수집 관련 보안 사항, 개인정보보호 관련 문제 등 점검 필수
-
데이터 유형 분류 및 확인
- 수집 대상 데이터 유형을 분류하고 데이터 포맷 등 확인
-
수집 기술 선정
- 데이터 유형 및 포맷 등에 맞는 수집 기술 선정
- 수집 기술은 데이터 소스로부터 다양한 유형의 데이터를 수집하기 위해 확정성, 안정성, 실시간성 및 유연성 확보 필요
-
수집 계획서 작성
- 수집 대상 ‘데이터 출처, 수집 기술, 수집 주기 및 수집 담당자의 주요 업무’등을 반영하여 계획서 작성
-
수집 주기 결정
- 데이터 유형에 따라 배치 또는 실시간 방식 적용
-
데이터 수집 실행
- 사전 테스트 진행하고 데이터 수집 시행
Paragraph 2. 수집 데이터의 대상
수집 데이터 대상은 데이터의 위치에 따라 내부 데이터와 외부 데이터로 구분한다.
-
내부 데이터
- 조직(인프라) 내부에 데이터가 위치하며, 데이터 담당자와 수집 주기 및 방법 등을 협의하여 데이터를 수집
- 내부 조직 간 협의를 통한 데이터 수집
- 주로 수집이 용이한 정형 데이터
- 서비스의 수명 주기 관리가 용이
-
서비스
SCM, ERP, CRM, 포털, 원장정보 시스템, 인증 시스템, 거래 시스템
-
네트워크
백본, 방화벽, 스위치, IPS, IDS
-
마케팅
VOC 접수 데이터, 고객 포털 시스템 등
-
외부 데이터
- 조직(인프라) 외부에 데이터가 위치하며, 특정 기관의 담당자 협의 또는 데이터 전문 업체를 통해 데이터를 수집
- 공공 데이터의 경우에는 공공 데이터 포털을 통해 Open API 또는 파일을 통해 수집
- 외부 조직과 협의, 데이터 구매, 웹상의 오픈 데이터를 통한 데이터 수집
- 주로 수집이 어려운 비정형 데이터
- 소셜
SNS, 커뮤니티, 게시판
- 네트워크
센서 데이터, 장비 간 발생 로그(M2M)
- 공공
정부 공개 경제, 의료, 지역정보, 공공 정책, 과학, 교육, 기술 등의 공공 데이터(LOD)
Paragraph 3. 데이터 수집 방식 및 기술
- 수집 대상 데이터는 데이터의 구조적 관점에 따라 정형 데이터, 비정형 데이터, 반정형 데이터로 나눌 수 있다.
- 구조적 관점에 따라 분류된 데이터 유형에 따라 각각 데이터 수집 방식과 기술을 최적화하여 적용해야 한다.
Subparagraph 1. 정형 데이터 수집 방식 및 기술
정형 데이터에 대한 수집 방식과 기술에는 ETL, FTP, API, DBToDB, Rsync, 스쿱(Sqoop)이 있다.
- ETL(Extract Transform Load)
- 수집 대상 데이터를 추출, 가공(변환, 정제)하여 데이터 웨어하우스 및 데이터 마트에 저장하는 기술
- FTP(File Transfer Protocol)
- 원격지 시스템 간에 파일을 공유하기 위한 서버, 글라이언트 모델로 TCP/IP 기반으로 파일을 송·수신하는 응용계통 통신 프로토콜
- 최근 서버와 클라이언트 사이의 파일 전송 시 보안성을 강화하기 위해 SSH(Secure Shell)를 적용한 SFTP 사용 권고
- API(Application Programming Interface)
- 솔루션 제조사 및 3rd party 소프트웨어로 제공되는 도구로서, 시스템 간 연동을 통해 실시간으로 데이터를 수신할 수 있는 기능을 제공하는 인터페이스 기술
- DBToDB
- 데이터베이스 시스템 간 데이터를 동기화하거나 전송하는 기능을 제공하는 기술
- Rsync(Remote Sync)
- 서버 클라이언트 방식으로 수집 대상 시스템과 1:1로 파일과 디렉터리를 동기화하는 응용 프로그램 활용 기술
- Sqoop
- Connector를 사용하여 RDB와 하둡 간 데이터 전송 기능을 제공하는 기술
- Sqoop은 모든 적재 과정을 자동화하고 병렬 처리 방식으로 작업
Clause 1. ETL(Extract Transform Load)
데이터 분석을 위한 데이터를 데이터 저장소인 DW(Data Mart) 및 DM(Data Mart)으로 이동시키기 위해 다양한 소스 시스템으로부터 필요한 원번 데이터를 추출(Extract)하고 변환(Transform)하여 적재(Load)하는 작업 및 기술이다

⬇ETL 프로세스
- 추출(Extract)
- 동일 기종 또는 이기종 소스 데이터베이스로부터 데이터를 추출
- JDBC, ODBC, 3rd Party Tools 활용
- 변환(Transfrom)
- 조회 또는 분석을 목적으로 적절한 포맷이나 구조로 데이터를 저장하기 위해 데이터 변환
- 데이터 결합/통합, 데이터 재구성 및 중복 데이터 제거, 일관성 확보를 위한 정제 수행, Rule 적용, 데이터 표준화 수행
- 적재(Load)
- 추출 및 변환된 데이터를 최종 대상(DW 또는 DM)에 저장
- Insert, Delete, Update, Append 수행
Clause 2. FTP(File Transfer Protocol)
TCP/IP 프로토콜을 기반으로 서버, 클라이언트 사이에서 파일 송·수신을 하기 위한 프로토콜(TCP 프로토콜을 사용하고 20, 21번 포트 번호를 사용)이다.

⬇FTP 유형
- Active FTP
- 클라이언트가 데이터를 수신받을 포트를 서버에 알려주면, 서버가 자신의 20번 포트를 통해 클라이언트의 임의의 포트로 데이터를 전송해 주는 방식
- 명령은 21번 포트, 데이터는 20번 포트를 사용
- Passive FTP
- 서버가 데이터를 송신해줄 임의의 포트를 클라이언트에 알려주면 클라이언트가 서버의 임의의 포트로 접속해서 데이터를 가져가는 방식
- 명령은 21번 포트, 데이터는 1024 이후의 포트를 사용
Clause 3. 스쿱(Sqoop)
- 스쿱은 커넥터(Connector)를 사용하여 MySQL 또는 Oracle, 메인 프레임과 같은 RDBMS에서 HDFS으로 데이터를 수집하거나, HDFS에서 RDBMS로 데이터를 보낼 수 있다.
⬇스쿱 특징
- 벌크 임포트(Bulk Import) 지원
- 전체 데이터베이스 또는 테이블을 HDFS로 한 번에 전송 가능
- 데이터 전송 병렬화
- 시스템 사용율과 성능을 고려한 병렬 데이터 전송
- 직접 입력 제공
- RDB에 매핑해서 HBase와 Hive에 직접 import 제공
- 프로그래밍 방식의 데이터 인터랙션
- 자바 클래스 생성을 통한 데이터 상호작용
⬇스쿱 주요 기능
- 구조
- 스쿱 클라이언트
- 스쿱 1에서 지원하며, 클라이언트 기반으로 import와 export를 제공
- 스쿱 서버
- 스쿱 2에서 지원하며, 클라이언트의 요청을 받아 작업을 수행
- 스쿱 클라이언트
- 커넥터(Connector)
- FTP 커넥터
- FTP 서버와 다른 스쿱 2 커넥터 간에 데이터 이동 지원
- JDBC 커넥터
- JDBC 4를 지원하는 모든 데이터베이스에 연결하여 데이터 이동 지원
- HDFS 커넥터
- HDFS 연결을 통해 데이터 이동 지원
- 카프카 커넥터
- Kafka 연결을 통해 데이터 이동 지원
- Kite 커넥터
- Kite 연결을 통해 데이터 이동 지원
- SFTP 커넥터
- 보안이 강화된 SFTP 서버와 다른 스쿱 2 커넥터 간에 데이터 이동 지원
- FTP 커넥터
- 툴(Tools)
- Import
- 다른 저장소(RDBMS)의 데이터를 명기된 저장소(HDFS, Hive, Hbase)로 가져오기 기능
- Export
- 저장소의 데이터를 다른 저장소(RDBMS)로 내보내기 기능
- Job
- 지정된 잡(Job)의 생성, 실행 기능
- Metastore
- 공유된 메타데이터 저장소를 호스팅할 수 있도록 구성하는 기능
- Merge
- 동일한 데이터를 포함하는 두 개의 데이터 세트를 병합하는 기능
- Import
- 정형 데이터 수집 방식 중 스쿱을 이용한 Hadoop과 RDBMS간의 데이터 전송, 수집 방식은 모든 과정이 자동화되어 처리된다.
Subparagraph 2. 비정형 데이터 수집 방식 및 기술
비정형 데이터에 대한 수집 방식과 기술에는 Crawling, RSS, Open API, Scrapy, Apache Kafka 등이 있다
⬇비정형 데이터 수집 방식 및 기술
- Crawling
- 인터넷상에서 제공되는 다양한 웹 사이트로부터 소셜 네트워크 정보, 뉴스, 게시판 등의 웹 문서 및 콘텐츠 수집 기술
- RSS(Rich Site Summary)
- 블로그, 뉴스, 쇼핑몰 등의 웹 사이트에 게시된 새로운 글을 공유하기 위해 XML 기반으로 정보를 배포하는 프로토콜을 활용하여 데이터를 수집하는 기술
- Open API
- 응용 프로그램을 통해 실시간으로 데이터를 수신할 수 있도록 공개된 API를 이용하여 데이터를 수집하는 기술
- Scrapy
- 웹 사이트를 크롤링하여 구조화된 데이터를 수집하는 Python기반의 애플리케이션 프레임워크로서 데이터 마이닝, 정보 처리, 이력 기록 같은 다양한 애플리케이션에 사용되는 수집 기술
- Apache Kafka
- 대용량 실시간 로그 처리를 위해 기존 메시징 시스템과 유사하게 레코드 스트림을 발행(Publish), 구독(Scriber)하는 방식의 분산 스트리밍 플랫폼 기술
Clause 1. 스크래파이(Scrapy)
스크래파이는 파이썬 언어 기반의 비정형 데이터 수집 기술이다
- 특징
- 파이썬 기반
- 파이썬 언어 기반으로 구성, 설정이 쉬움
- 단순한 스크랩 과정
- 크롤링 수행 후 바로 데이터 처리 가능
- 다양한 부가 요소
- scrapyd, scrapinghub 등 부가 기능, 쉬운 수집, 로깅 지원
- 파이썬 기반
- 주요 기능
- Spider
- 크롤링 대상 웹 사이트 및 웹 페이지의 어떤 부분을 스크래핑할 것인지를 명시하는 기능
- Selector
- 웹 페이지의 특정 HTML 요소를 선택하는 기능
- LXML 기반으로 제작 가능
- Items
- 웹 페이지를 스크랩하여 저장할 때 사용되는 사용자 정의 자료 구조
- Pipelines
- 스크래핑 결과물을 아이템 형태로 구성할 때 가공하거나 파일 형태로 저장 제공 기능
- Settings
- Spider와 Pipeline을 동작시키기 위한 세부 설정
- Spider
Clause 2. 아파치 카프카(Apache Kafka)
- 아파치 카프카는 대용량 실시간 로그 처리를 위한 분산 스트리밍 플랫폼이다
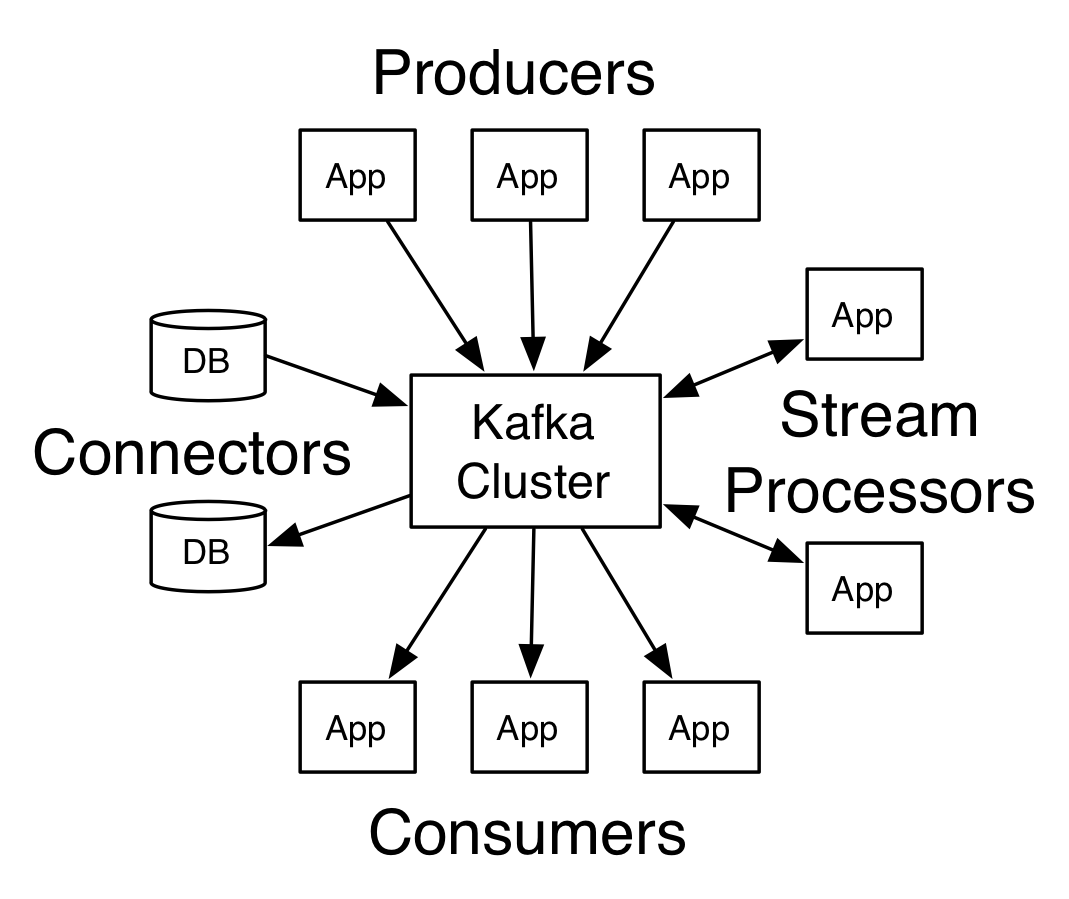
⬇카프카 특징 및 주요 기능
- 특징
- 신뢰성(Reliability) 제공
- 메모리 및 파일 큐 기반의 채널 지원
- 확장성(Scalability) 제공
- Multi Agent와 Consolidation, Fan Out Flow 방식으로 구성되어 수평 확장(Scale-Out)이 가능하며, 수집 분산 처리가 가능
- 신뢰성(Reliability) 제공
- 주요 기능
- 소스(Source)
- 외부 이벤트 생성, 수집 영역
- 1개로 구성되며, 복수 개의 채널(Channel) 지정 가능
- 채널(Channel)
- 소스(Source)와 싱크(Sink) 간 버퍼 구간
- 채널별로 1개 싱크 지정
- 싱크(Sink)
- 채널로부터 수집된 로그 또는 이벤트를 목적지에 전달 및 저장
- 인터프리터(Interpreter)
- 수집된 로그 또는 이벤트를 가공
- 소스(Source)
- 비정형 데이터 수집 방식 및 기술에서는 스크래파이와 아파치 카프카의 활용이 증가되고 있다
Subparagraph 3. 반정형 데이터 수집 방식 및 기술
- 센싱(Sensing)
- 센서로부터 수집 및 생성된 데이터를 네트워크를 통해 수집 및 활용
- 스트리밍(Streaming)
- 네트워크를 통해 센서 데이터 및 오디오, 비디오 등의 미디어 데이터를 실시간으로 수집하는 기술
- 플럼(Flume)
- 스트리밍 데이터 흐름(Data Flow)을 비동기 방식으로 처리하는 분산형 로그 수집 기술
- 스크라이브(Scribe)
- 다수의 서버로부터 실시간으로 스트리밍되는 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술
- 척와(Chuckwa)
- 대규모 분산 시스템 모니터링을 위해 에이전트(Agent)와 컬렉터(Collector) 구성을 통해 데이터를 수집하고, 수집된 데이터를 HDFS에 저장하는 기능을 제공하는 데이터 수집 기술
Clause 1. 플럼(Flume)
많은 양의 로그 데이터를 효율적으로 수집, 집계, 이동하기 위해 이벤트(Event)와 에이전트(Agent)를 활용하는 기술
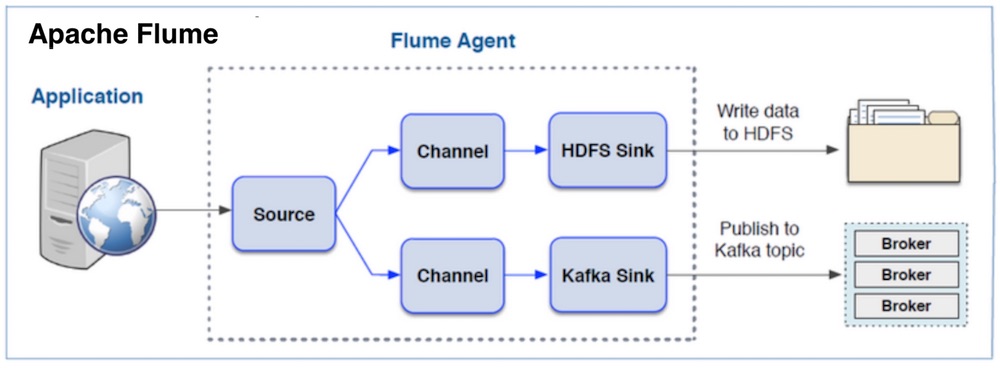
⬇플럼 특징 및 주요 기능
- 특징
- 발행(Publisher)/구독(Subscriber) 모델
- 메시지 큐와 유사한 형태의 데이터 큐를 사용
- 풀 방식으로 동작하여 부하 감소 및 고성능의 기능 제공
- 고가용성 제공
- 클러스터 구성을 통해 내결함성(Fault Tolerant)이 있는 고가용성 서비스 제공 가능
- 분산 처리 통한 빠른 실시간 데이터 처리
- 파일 기반 저장방식
- 데이터를 디스크에
- 발행(Publisher)/구독(Subscriber) 모델
- 주요 기능
- 소스(Source)
- 이벤트를 전달하는 컨테이너
- 소스, 채널, 싱크로 흐름 제어
- 에이전트 간 데이터 이도이 가능하며, 1개의 에이전트가 다수의 에이전트와 연결 가능
- 채널(Channel)
- 이벤트를 소스와 싱크로 전달하는 통로
- 싱크(Sink)
- 채널로부터 받은 이벤트를 저장, 전달
- 싱크 대상을 다중 선택하거나, 여러 개의 싱크를 그룹으로 관리
- 소스(Source)
Clause 2. 스크라이브(Scribe)
- 다수의 서버로부터 실시간으로 스트리밍되는 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술이다
- 단일 중앙 스크라이브 서버와 다수의 로컬 스크라이브 서버로 구성되어 안정성과 확장성을 제공한다
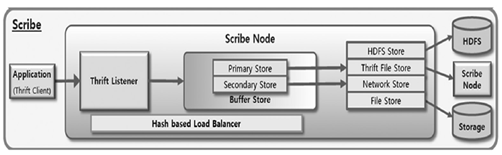
⬇스크라이브 특징
- 실시간 스트리밍 수집
- 다수의 서버로부터 실시간으로 스트리밍되는 로그 수집 가능
- 확장
- 아파치 Thrift 기반 스크라이브 API를 활용하여 확장 가능
- 데이터 수집 다양성
- 클라이언트 서버 타입에 상관없이 로그 수집 가능
- 고가용성
- 단일 중앙 스크라이브 서버와 다중 로컬 스크라이브 서버로 구성
- 중앙 스크라이브 서버 장애 시, 로컬 스크라이브 서버에 데이터를 저장한 후, 중앙 스크라이브 서버 복구시 메시지를 전송
Clause 3. 척와(Chuckwa)
- 척와는 분산된 각 서버에서 에이전트를 실행하고, 컬렉터(Collector)가 에이전트로부터 데이터를 수집하여 HDFS에 저장, 실시간 분석 기능을 제공하는 기술
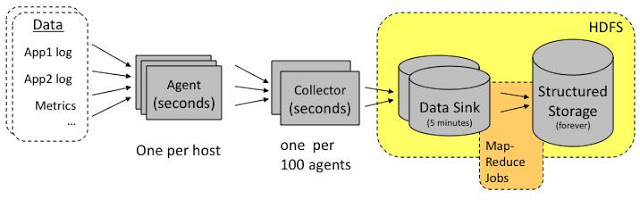
⬇척와 주요 기능
- 특징
- HDFS 연동
- 수집된 로그 파일을 HDFS에 저장하는 기능 지원
- 실시간 분석 제공
- HDFS을 통한 실시간 분석 지원
- 청크(Chunk) 단위 처리
- 어댑터가 데이터를 메타데이터가 포함된 청크 단위로 전송
- HDFS 연동
- 구성
- 에이전트(Agent)
- 어댑터를 포함한 에이전트를 통해 데이터 수집
- 컬렉터 페일 오버 기능과 체크 포인트(Check-Pint)를 통해 데이터 유실 방지 기능 제공
- 컬렉터(Collector)
- 에이전트로부터 수집된 데이터를 주기적으로 HDFS에 저장
- 여러 에이전트로부터 수신된 데이터를 단일 싱크(Sink) 파일에 저장(HDFS의 Sequence File 포맷으로 저장)
- 에이전트(Agent)
- 데이터 처리
- 아카이빙(Archiving)
- 컬렉터가 저장한 로그 파일에 대해 시간 순서로 동일한 그룹으로 묶는 작업 수행
- 데이터 중복 제거 및 정렬 작업을 수행하고 HDFS Sequence File 포맷으로 저장
- 디먹스(Demux)
- 로그 레코드를 파싱해서 Key-Value 쌍으로 구성되는 척와 레코드(Chuckwa Record)를 만들고, 하둡 파일 시스템에 파일로 저장
- 아카이빙(Archiving)
- 반정형 데이터 수집 방식 및 기술 중 플럼, 스크라이브, 척와의 활용은 점차 증가하고 있다