Article 2. 데이터 저장 1322
Section 2. 데이터 적재 및 저장
Paragraph 1. 빅데이터 저장기술
- 빅데이터 저장 시스템은 대용량 데이터 집합을 저장하고 관리하는 시스템으로 대용량의 저장 공간, 빠른 처리 성능, 확장성, 신뢰성, 가용성 등을 보장해야한다.
- 메타 데이터를 별도의 전용 서버로 관리하는 ‘비대칭형(Asymmetric) 클러스터 파일 시스템’이 개발되고 있다. 이 시슽쳄은 메타데이터에 접근하는 경로와 데이터에 접근하는 경로가 분리된 구조를 가진다.
Paragraph 2. 빅데이터 저장기술 분류
빅데이터 젖아기술은 분산 파일 시스템, 데이터베이스 클러스터, NoSQL, 클라우드 파일 저장 시스템 등으로 구분된다.
- 분산 파일 시스템
- 내용
- 컴퓨터 네트워크를 통해 공유하는 여러 호스트 컴퓨터의 파일에 접근할 수 있게 하는 파일 시스템
- 제품
- 구글 파일 시스템(GFS)
- 하둡 분산 파일 시스템(HDFS)
- 러스터(Lustre)
- 내용
- 데이터베이스 클러스터
- 내용
- 관계형 데이터베이스 관리 시스템으로 하나의 데이터베이스를 여러 개의 서버상에 구축하는 시스템
- 제품
- 오라클 RAC
- IBM DB2 ICE
- MSSQL, MySQL
- 내용
- NoSQL
- 내용
- 전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어로 데이터 저장에 고정된 테이블 스키마가 필요하지 않고 조인(Join) 연산을 사용할 수 없으며, 수평적으로 확장이 가능한 DBMS
- ACID 요건을 완화하거나 제약하는 특징
- 제품
- 구글 빅테이블
- HBase
- 아마존 SimpleDB
- 마이크로소프트 SSDS
- Cloudata, Cassandra
- 내용
- 병렬 DBMS
- 내용
- 다수의 마이크로프로세서를 사용하여 여러 디스크에 대한 질의, 갱신, 입출력 등의 데이터베이스 처리를 동시에 수행하는 데이터베이스 시스템
- 제품
- VoltDB
- SAP HANA
- Verica, Greenplum
- Netezza
- 내용
- 네트워크 구성 저장 시스템
- 내용
- 서로 다른 종류의 데이터 저장 장치를 하나의 데이터 서버에 연결하여 전체적으로 통합하여 데이터를 저장, 관리
- 제품
- SAN, NAS
- 내용
- 클라우드 파일 저장 시스템
- 내용
- 클라우드 컴퓨팅 환경에서 가상화 기술을 활용한 분산 파일 시스템
- 제품
- Amazon S3
- OpenStack Swift
- 내용
Paragraph 3. 빅데이터 저장기술 - 분산 파일 시스템 상세
Subparagraph 1. 구글파일 시스템
Clause 1. Google File System(GFS)의 개념
- GFS은 구글의 대규모 클러스터 서비스 플랫폼의 기반이 되는 파일 시스템이다.
- 파일을 고정된 크기(64MB)의 청크들로 나누며 각 청크와 여러 개의 복제본을 청크 서버에 분산하여 저장한다.
Clause 2. GFS의 구성요소
- 클라이언트(Client)
- 파일에 대한 읽기/쓰기 동작을 요청하는 애플리케이션으로 POSIX 인터페이스를 지원하지 않으며, 파일 시스템 인터페이스와 유사한 자체 인터페이스를 지원
- 여러 클라이언트에서 원자적인 데이터 추가(Atomic Append) 연산을 지원학 위한 인터페이스 지원
- 마스터(Master)
- 단일 마스터 구조로 파일 시스템의 이름 공간(Name Space), 파일과 청크의 매핑 정보, 각 청크가 저장된 청크 서버들의 위치정보 등에 해당하는 모든 메타데이터를 메모리상에서 관리
- 주기적으로 청크 서버의 하트비트 메시지를 이용하여 청크를 재복사하거나 재분산하여 상태를 관리
- 청크 서버(Chunk Server)
- 로컬 디스크에 청크를 저장
- 클라이언트가 청크 입출력을 요청하면 청크 서버가 처리
- 주기적으로 청크 서버의 상태를 하트비트 메시지로 마스터에게 전달
Clause 3. GFS의 구조
클라이언트가 GFS 마스터에게 파일을 요청하면, 마스터는 저장된 청크의 매핑 정보를 찾아서 해당 청크 서버에 전송을 요청하고, 해당 청크 서버는 클라리언트에게 청크 데이터를 전송한다.

Subparagraph 2. HDFS
Clause 1. HDFS의 개념
수십 테라바이트 또는 페타바이트 이상의 대용량 파일을 분산된 서버에 저장하고, 저장된 데이터를 빠르게 처리할 수 있게 하는 분산 파일 시스템이다.
Clause 2. HDFS의 특징
- 저사양의 다수의 서버를 이용해서 스토리지를 구성할 수 있어 기존의 대용량 파일 시스템(NAS, DAS, SAN 등)에 비해 비용관점에서 효율적이다.
- HDFS는 블록 구조의 파일 시스템으로 파일을 특정 크기의 블록으로 나누어 분산된 서버에 저장된다.
- 블록 크기는 64MB에서 하둡 2.0부터는 128MB로 증가되었다.
Clause 3. HDFS의 구성요소
- HDFS는 하나의 네임 노드(Name Node)와 하나 이상의 보조 네임 노드, 다수의 데이터 노드(Data Node)로 구성된다.
- HDFS의 네임 노드는 GFS의 마스터, 데이터 노드는 청크 서버와 유사하다.
- 네임 노드(Name Node)
- HDFS 상의 모든 메타데이터를 관리하며 마스터/슬레이브 구조에서 마스터 역할 수행
- 데이터 노드들로부터 하트비트를 받아 데이터 노드들의 상태를 체크하는데, 하트비트 메시지에 포함된 정보를 가지고 블록의 상태 체크
- 보조네임 노드(Secondary Name Node)
- HDFS 상태 모니터링을 보조
- 주기적으로 네임 노드의 파일 시스템 이미지를 스냅샷으로 생성
- 데이터 노드(Data Node)
- HDFS의 슬레이브 노드로, 데이터 입출력 요청을 처리
- 데이터 유실 방지를 위해 블록을 3중으로 복제하여 저장

Subparagraph 3. 러스터
Clause 1. 러스터(Lustre) 개념
클러스터 파일 시스템(Cluster File System Inc.)에서 개발한 객체 기반의 클러스터 파일 시스템이다.
Clause 2. 러스터(Lustre) 구성요소
- 고속 네트워크로 연결된 클라이언트 파일 시스템, 메타데이터 서버, 객체 저장 서버들로 구성된다.
- 계층화된 모듈 구조로 TCP/IP, 인피니밴드 같은 네트워크를 지원한다.
- 클라이언트 파일 시스템
- 리눅스 VFS(Virtual File System)에서 설치할 수 있는 파일 시스템
- 메타데이터 서버와 객체 저장 서버들과 통신하면서 클라이언트 응용에 파일 시스템 인터페이스를 제공
- 메타데이터 서버
- 파일 시스템의 이름 공간과 파일에 대한 메타데이터를 관리
- 객체 저장 서버
- 파일 데이터를 저장하고, 클라이언트로부터의 객체 입출력 요청을 처리
- 데이터는 세그먼트라는 작은 데이터 단위로 분할해서 복수의 디스크 장치에 분산시키는 기술인 ‘스트라이핑 방식’으로 분산, 저장
Paragraph 4. 빅데이터 저장기술 - 데이터베이스 클러스터 상세
Subparagraph 1. 데이터베이스 클러스터(Database Cluster) 개념
데이터베이스 클러스터는 하나의 데이터베이스를 여러 개의 서버상에 분산하여 구축하는 것을 의미한다.
Subparagraph 2. 데이터베이스 클러스터 특징
- 데이터를 통합할 때, 성능과 가용성의 향상을 위해 데이터베이스 파티셔닝 또는 클러스터링을 이용한다.
- 데이터베이스 시스템을 구성하는 형태에 따라 단일 서버 파티셔닝과 다중 서버 파티셔닝으로 구분한다.
Subparagraph 3. 데이터베이스 클러스터 구분
리소스 공유 관점에서는 공유 디스크와 무공유 디스크로 구분한다.

- 공유 디스크 클러스터(Shared Disk Cluster)
- 데이터 파일은 논리적으로 데이터 파일을 공유하여 모든 데이터에 접근 가능하게 하는 방식
- 데이터 공유를 위해 SAN(Storage Area Network)과 같은 네트워크 장비가 있어야 함
- 모든 노드가 데이터를 수정할 수 있어, 동기화 작업을 위한 채널이 필요
- 높은 수준의 고가용성을 제공하므로 클러스터 노드 중 하나만 살아 있어도 서비스가 가능
- 무공유 클러스터(Shared Nothing Cluster)
- 무공유 클러스터에서 각 데이터베이스 인스턴스는 자신이 관리하는 데이터 파일을 자신의 로컬 디스크에 저장하며, 이 파일들은 노드 간에 공유하지 않음
- 노드 확장에 제한이 없지만, 각 노드에 장애가 발생할 경우를 대비해 별도의 FTA를 구성해야 함
Subparagraph 4. 데이터베이스 클러스터 종류
- Oracle RAC
- Oracle RAC는 공유 클러스터에 해당되므로, 클러스터의 모든 노드에서 실행되며 데이터는 공유 스토리지에 저장
- 고가용성과 확장이 쉬운 장점이 있음
- IBM DB2 ICE(Integrated Cluster Environment)
- DB2는 CPU, 메모리, 디스크를 파티션별로 독립적으로 운영하는 무공유 방식의 클러스터링 지원
- 독립적으로 운영되므로 하나의 노드에 장애가 발생하면 복구할 수 있도록 공유 디스크 방식을 사용하여 가용성 보장
- SQL Server
- SQL Server는 연합(Federated) 데이터베이스 형태로 여러 노드로 확장할 수 있는 기능 제공
- 가용성을 확보할 수 있도록 페일오버를 제공하지만, Active-Active가 아닌 Active-Standby 방법을 사용
- MySQL
- 비 공유형으로 메모리 기반 데이터베이스의 클러스터링 지원
- 관리, 데이터, MySQL 노드로 구성
- 데이터는 동기화 방식으로 복제되며, 이 작업을 위해 데이터 노드 간에는 별도의 네트워크 구성
Paragraph 5. 빅데이터 저장기술 - NoSQL
Subparagraph 1. NoSQL(Not Only SQL)의 개념
NoSQL은 전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어로 데이터 저장에 고정된 테이블 스키마가 필요하지 않고 조인(Join) 연산을 사용할 수 없으며, 수평적으로 확장이 가능한 DBMS이다.
Subparagraph 2. NoSQL의 일반적 특성
- NoSQL은 관계형 모델을 사용하지 않는 데이터 저장소 또는 인터페이스이며, 대규모 데이터를 처리하기 위한 기술로 확장성, 가용성, 높은 성능을 제공한다.
- 스키마-리스(Schema-less)로 고정된 스키마 없이 자유롭게 데이터베이스의 레코드에 필드를 추가할 수 있다.
- 대부분 오픈 소스이며 구글 BigTable, 아파치 HBase, 아마존 SimpleDB, 마이크로소프트 SSDS 등이 있다.
Subparagraph 3. NoSQL의 특성(BASE)
- Basically Available
- 언제든지 데이터는 접근할 수 있어야 하는 속성
- 분산 시스템이기 때문에 항상 가용성 중시
- Soft-State
- 노드의 상태는 내부에 포함된 정보에 의해 결정되는 것이 아니라 외부에서 전송된 정보를 통해 결정되는 속성
- 특정 시점에는 데이터의 일관성이 보장되지 않음
- Eventually Consistency
- 일정 시간이 지나면 데이터의 일관성이 유지되는 속성
- 일관성을 중시하고 지향
Subparagraph 4. NoSQL의 유형
- NoSQL은 저장되는 데이터의 구조에 따라 Key-Value, Column Family Data, Document, Graph Store로 구분된다.
-
Key-Value Store
-
Unique 한 Key에 하나의 Value를 가지고 있는 형태
-
키 기반 Get / Put / Delete 제공하는 빅데이터 처리 가능 DB
예) Redis, DynamoDB
-
-
Column Family Data Store
-
Key 안에 (Column, Value) 조합으로 된 여러 개의 필드를 갖는 DB 테이블 기반, 조인 미지원, 컬럼 기반, 구글의 BigTable 기반으로 구현
예) HBase, Cassandra
-
-
Document Store
-
Value의 데이터 타입이 Document라는 타입을 사용하는 DB
-
Document 타입은 XML, JSON, YAML과 같이 구조화된 데이터 타입으로, 복잡한 계층 구조를 표현할 수 있음
예) MongoDB, Couchbase
-
-
Graph Store
-
시맨틱 웹과 온톨로지 분야에서 활용되는 그래프로 데이터를 표현하는 DB
예) Neo4j, AllegroGraph
-
Subparagraph 5. CAP 이론
- 분산 컴퓨팅 환경은 Availability, Consistency, Partition Tolerance 3가지 특징을 가지고 있으며, 이 중 두 가지만 만족할 수 있다는 이론이다.
- NoSQL은 CAP 이론을 기반으로 하고 있다.
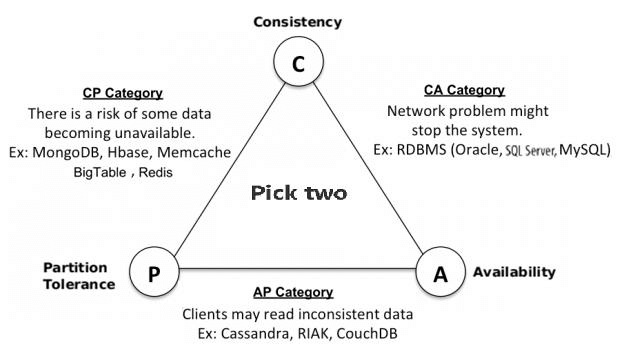
- 유효성(Availability)
- 모든 클라이언트가 읽기 및 쓰기가 가능해야 한다는 특성
- 하나의 노드에 장애가 일어나더라도 다른 노드에는 영향을 미치면 안 되는 특성
- 일관성(Consistency)
- 모든 사용자에게 같은 시간에는 같은 데이터를 보여주어야 한다는 특성
- 분산 가능(Partition tolerance)
- 물리적 네트워크 분산 환경에서 시스템이 원활하게 통작해야 한다는 특성
- 네트워크 전송 중 데이터 손실 상황이 생겨도 시스템은 정상적으로 동작해야 한다는 특성
Subparagraph 6. NoSQL 제품 종류
- 구글 빅테이블
- 구글 클라우드 플랫폼에서 데이터 저장소로 사용
- 공유 디스크 방식으로 모든 노드가 데이터, 인덱스 파일 공유
- row는 n개의 Column-Family를 가질 수 있음
- 같은 컬럼 키에 대해 다른 여러 버전의 타임스탬프가 존재할 수 있음
- 빅테이블의 SPOF는 마스터이며, 분산 락 서비스를 제공하는 Chubby를 이용해 마스터 장애 시 가용한 노드를 마스터로 변경
- HBase
- HDFS를 기반으로 구현된 컬럼 기반의 분산 데이터베이스
- HBase는 비관계형이며 SQL을 지원하지 않음
- RDBMS와 달리 수평적으로 확장성이 있어 큰 테이블에 적합, 단일 행의 트랜잭션을 보장
- 아마존 SimpleDB
- Amazon의 데이터 서비스 플랫폼으로, 웹 애플리케이션에서 사용하는 데이터의 실시간 처리를 지원
- Amazon의 다른 플랫폼 서비스와 같이 사용
- 마이크로소프트 SSDS
- SSDS(SQL Server Data Service)는 고가용성 보장
- 데이터 모델은 테이블과 유사한 컨테이너, 레코드와 유사한 엔티티로 구성
- 컨테이너의 생성/삭제, 엔티티의 생성/삭제, 조회, 쿼리 등의 API를 제공하고 SOAP/REST 기반의 프로토콜 지원
Paragraph 6. 빅데이터 저장 고려사항
Subparagraph 1. 빅데이터 저장 제품 검토
- 빅데이터 저장을 위한 제품을 검토하기 위해 사용자 요구사항을 분석한다.
- 요구사항 분석은 요구사항을 수집하고, 이를 분석하여 명세하고 검증을 통해 확정하는 4단계로 수행한다.
⬇요구사항 분석 절차
- 요구사항 수집(도출)
- 설명
- 문서나 인터뷰를 통해 수집하거나 기존 시스템 분석을 통해 요구사항을 수집
- 예시
- 제안요청서
- 포커스 그룹 인터뷰
- 설문
- 워크숍
- 설명
- 요구사항 분석
- 설명
- 기능, 비기능 데이터 및 기타 요구사항을 분석
- 예시
- 데이터 유형
- 데이터 업데이트 주기
- 설명
- 요구사항 명세
- 설명
- 요구사항을 문서화하여 정리하는 과정
- 메타 정보, 변경 이력, 요구사항 목록으로 구성
- 예시
- 사용자 요구 명세서
- 설명
- 요구사항 검증
- 설명
- 요구사항 명세서를 배포하고 검토 회의를 통해 검증
- 예시
- 요구사항 리뷰 및 검토 회의
- 설명
⬇요구사항 명세서 사례
| 요구사항 ID | 요구사항 명 | 유형 | 관련 요구사항 | 요구사항 설명 | 우선 순위 | 수용 여부 | 비고 |
|---|---|---|---|---|---|---|---|
| DR-01-001 | 실내환경 모니터링 | 데이터 | SFR-02-003 | 온습도 센서값 저장 | 상 | 가 | 정형 10초 |
⬇빅데이터 분석기술 유형에 따른 기능 요구사항 예시
| 빅데이터 기술 유형 | 기능 요구사항 예시 |
|---|---|
| 연관 규칙 마이닝 | A상품을 구매하는 고객이 B 상품을 같이 구매하는지 확인할 수 있어야 한다. |
| 분류 분석 | 특정 고객이 어떤 특성을 갖는 고객 집단에 속하는지 확인할 수 있어야 한다. |
| 머신러닝 | 기존 영화 구매 패턴을 분석하여 고객에서 특정 영화를 추천할 수 있어야 한다. |
| 감정분석 | 신규 상품에 대한 고객의 반응을 분석할 수 있어야 한다. |
| 회귀 분석 | 구매자의 연령대와 구매 상품의 종류와 특성에 어떤 영향을 미치는지 분석할 수 있어야 한다. |
| 소셜 네트워크 분석 | 고객사의 소셜 네트워크상에서의 레퓨테이션은 어떠한지 상시로 모니터링할 수 있어야 한다. |
| 유전 알고리즘 | 응급실에서 응급처치 프로세스를 어떻게 배치하는 것이 가장 효율적인지 추천 할 수 있어야 한다. |
⬇요구사항 명세서 문서 양식 사례
| 요구사항 ID | 요구사항 명 | 유형 | 관련 요구사항 | 요구사항 설명 | 우선 순위 | 수용 여부 | 비교 |
|---|---|---|---|---|---|---|---|
| SFR-01-001 | 구매내역 저장 | 데이터 | SFR-02-003 | 고객이 상품을 구매한 내역을 시간순으로 저장해야 한다. | 상 | 가 |
Subparagraph 2. 기존 시스템 기술 검토 절차 수립
- 저장대상 데이터의 유형이 대부분 테이블로 정의될 수 있는 형태이고 기존에 RDBMS 기반의 데이터 웨어하우스가 도입된 형태라면 기존 시스템을 그대로 활용하여 빅데이터를 저장한다.
- 기존에 HDFS을 활용하여 빅데이터 저장시스템이 구축되어 있으나, SQL-like 분석환경을 구축하고자 한다면 HBase를 추가로 도입하는 것을 권장한다.
Subparagraph 3. 데이터 저장의 안정성, 신뢰성 확보 방안 수립
- 용량산정
- 빅데이터 저장 시스템의 안정성 및 신뢰성을 확보하고 보장하기 위해 저장 계획 수립단계에서 용량산정이 필요
- 조직의 빅데이터 활용 목적에 부합하는 현재와 향후 증가 추세를 추정 반영하여 빅데이터 저장 용량을 산정하여 계획하고 전체 저장 시스템 구축계획에 반영하는 것은 필수적
- 데이터, 아카이브 및 여유율 등을 고려하여 적정 디스크 용량 계획을 산정
- 데이터 파악
- 저장대상이 되는 데이터의 유형, 크기, 저장방식 및 기간 등을 파악
- 시스템 구축 방안
- 프라이빗 클라우드, 퍼블릭 클라우드와 같이 안정성 및 신뢰성을 고려한 시스템 구축방안을 계획
- 저장 시스템의 사용자와 관리자 유형, 역할 및 기능을 정의하고 각각에 해당하는 제어계획을 수립한다.
Subparagraph 4. 유형별 데이터 저장방식 수립
- 빅데이터 요구사항 분석 단계에서 요구사항에 따른 수집 및 저장이 필요한 데이터를 유형별로 분류하고 수집 주기 등의 특성을 분석하여야 한다.
- 요구사항에 따라 수집 및 저장관리가 필요한 데이터 종류를 데이터 유형별로 분류하고, 해당 데이터를 저장 관리하기에 적합한 저장 시스템을 선택해야 한다.
| 데이터 유형 | 요구 데이터 종류 | 저장 시스템 사례 |
|---|---|---|
| 정형 데이터 | RDB, 스프레드시트 | RDB(Oracle, MSSQL, MySQL, Sybase 등) |
| 반정형 데이터 | HTML, XML, JSON, 웹 문서, 웹 로그, 센서 데이터 | RDB, NoSQL(MongoDB, Redis, Cassandra, HBase 등) |
| 비정형 데이터 | 소셜 데이터, 문서(워드, 한글), 이미지, 오디오, 비디오, IoT | NoSQL, HDFS |
Subparagraph 5. 저장방식 결정
Clause 1. 빅데이터 저장시스템 선정을 위한 분석
빅데이터 저장시스템을 선정하기 위해서는 각 시스템이나 저장기술의 기능성, 분석 방식 및 유형, 분석 대상 데이터의 유형, 기존 시스템과의 연계성을 고려해야 한다.
- 저장기술의 기능성
- 데이터 모델이 무엇인지 고려(Key-Value 구조, Column Family 구조, Document 구조 중 선정)
- 확장성 고려
- 트랜잭션의 일관성이 중요한 분야에서는 RDBMS를 선택
- 분석 방식 및 환경
- 온라인 상시 또는 배치 기반 방식 고려
- 파일 시스템 형식, NoSQL, DW으로 구성할지 고려
- 분석 대상 데이터 유형
- 기업 내/외부 데이터 고려
- 데이터 발생량/속도 고려
- 데이터의 Volume,Velocity, Variety(3V)를 고려
- 기존 시스템과의 연계
- 운영 시스템과 연계(기존 RDBMS 유지, HDFS는 HBase 구성 권장, 키-값 쌍 구조는 Redis 도입 권장, IoT 데이터는 Cassandra 권장)
Clause 2. 저장방식 결정
빅데이터 저장 시스템 선정을 위한 분석 과정을 통해 검토된 항목은 선정 결과서에 작성하여 공유한다.
⬇빅데이터 저장방식 선정 결과서 예시
- 저장기술의 기능성
- 세부 고려 사항
- 데이터 모델
- 확장성
- 트랜잭션 일관성
- 질의지원
- 접근성
- 선정 검토 내역
- 테이블 형태 아닌 로그성 데이터 수집 저장: NoSQL
- 확장성이 너무 좋지 않아도 됨
- 데이터 일관성이 반드시 보장 안 되도 됨
- SQL이나 그에 준하는 질의 방법 필요
- Java 등 다양한 웹 시스템에서 접근 필요
- 세부 고려 사항
- 분석 방식 및 환경
- 세부 고려 사항
- 온라인 상시 또는 배치 기반
- 선정 검토 내역
- 배치기반의 분석도 있지만, 온라인으로 실시간 분석이 필요한 때도 있음
- 세부 고려 사항
- 데이터 유형
- 세부 고려 사항
- 기업 내/외부 데이터
- 데이터 발생량/속도
- 선정 검토 내역
- 기업 내부의 시스템 운영에 따른 다양한 로그성 데이터
- 1일 1만 건 이상의 데이터가 지속해서 발생
- 세부 고려 사항
- 기존 시스템과 연계
- 세부 고려 사항
- 운영 시스템과 연계
- 선정 검토 내역
- 기존 운영 시스템의 로그 데이터를 활용하는 것이므로 연계는 중요도가 높지 않음
- 세부 고려 사항
- 선정 검토 결과
- 다양한 로그성 데이터를 저장하고 분석하여 여러 웹 시스템과 연계할 필요가 있으므로, NoSQL 저장시스템이면서 확장성과 접근성이 좋은 MongoDB나 유사한 NoSQL로 구축 권장