Article7. 군집 분석 3217
Section 1. 분석기법
Paragraph 1. 군집 분석(Cluster Analysis)의 개념
군집 분석은 관측된 여러 개의 변숫값들로부터 유사성(Similarity)에만 기초하여 n개의 군집으로 집단화하여 집단의 특성을 분석하는 다변량 분석기법이다.
Paragraph 2. 군집 분석 종류 ㅡ 계층적 군집
Subparagraph 1. 계층적 군집(Hierarchical Clustering) 개념
유사한 개체를 군집화하는 과정을 반복하여 군집을 형성하는 방법이다.
Subparagraph 2. 계층적 군집을 형성하는 방법
계층적 군집을 형성하는 방법에는 병합적 방법과 분할적 방법이 있다.
| 형성 방법 | 설명 |
|---|---|
| 병합적 방법 (Agglomerative) |
• 작은 군집으로부터 시작하여 군집을 병합하는 방법 • 거리가 가까우면 유사성이 높음 • R 언어에서 stats 패키지의 hclust()함수와 cluster 패키지의 agnes(), mclust() 함수 이용 |
| 분할적 방법 (Divisive) |
• 큰 군집으로부터 출발하여 군집을 분리해 나가는 방법 • R 언어에서 cluster 패키지의 diana(), mona() 함수 이용 |
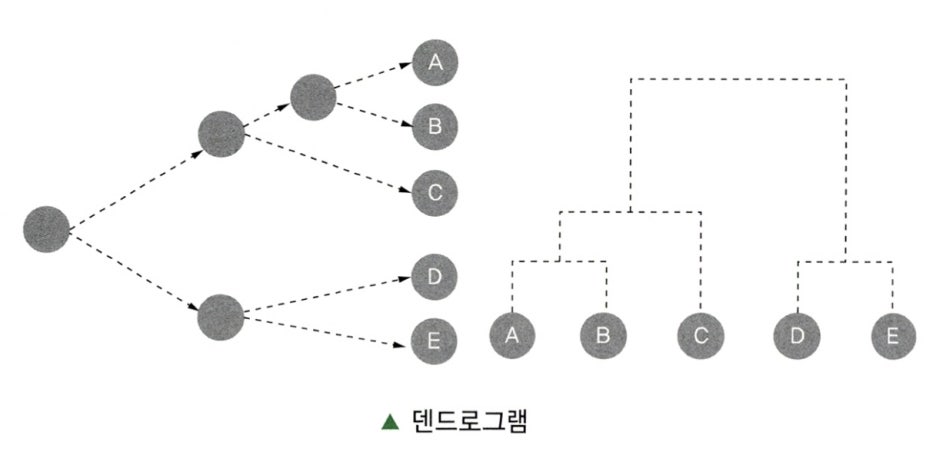
Subparagraph 3. 계통도
- 군집 결과는 계통도 또는
덴드로그램의 형태로 결과가 주어지며 각 개체는 하나의 군집에만 속하게 된다. - 항목 간의 거리, 군집 간의 거리를 알 수 있고, 군집 내 항목 간 유사 정도를 파악함으로써 군집의 견고성을 해석할 수 있다.
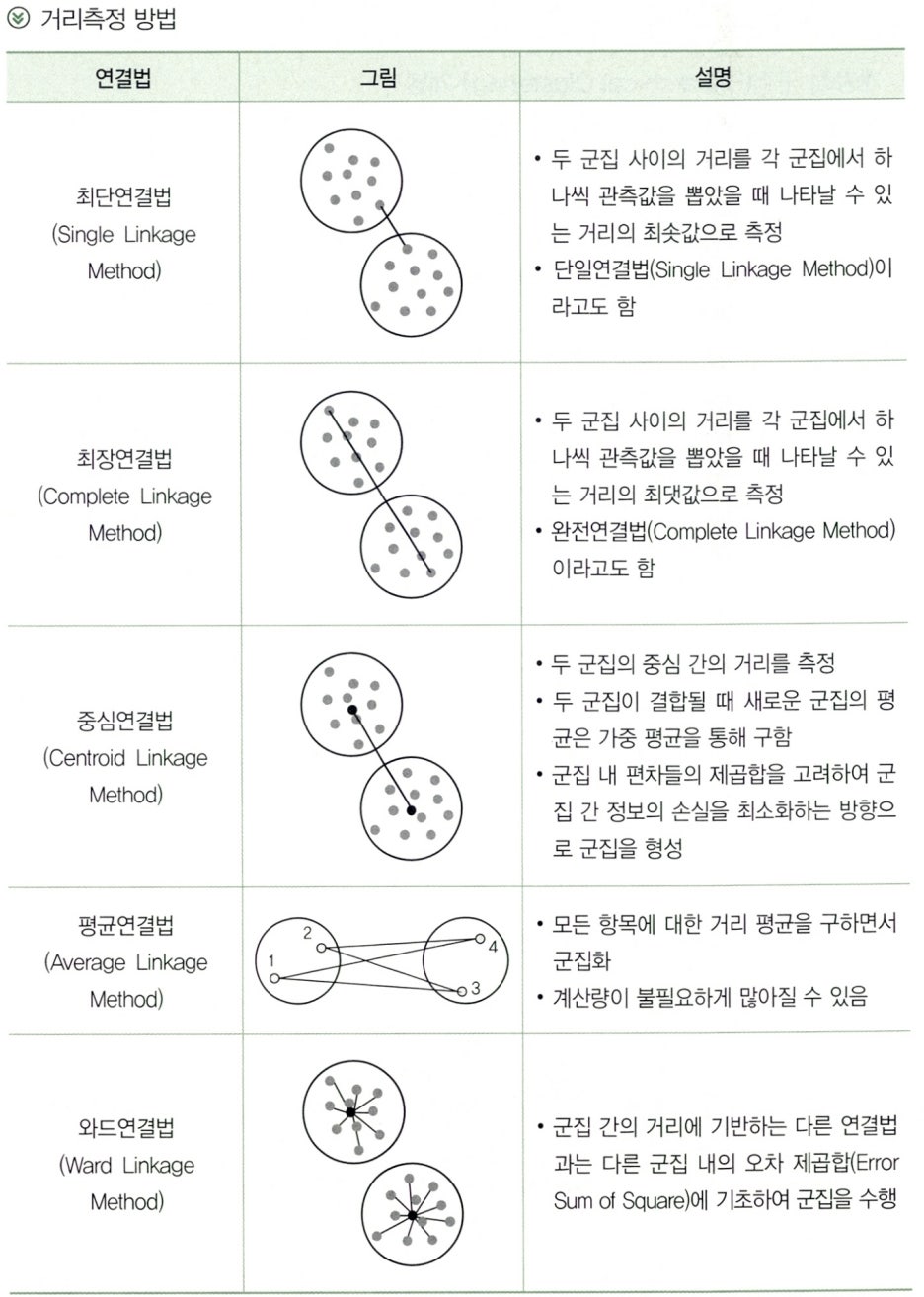
Subparagraph 4. 군집 간의 거리측정 방법
- 개체 간의 유사성(또는 거리)에 대한 다양한 정의가 가능하다.
- 군집 간의 연결법에는 최단연결법, 최장연결법, 평균 연결법, 중심연결법, 와드연결법이 있다.
- 군집 간의 연결법에 따라 군집의 결과가 달라질 수 있다.
Subparagraph 5. 군집 간의 거리 계산
Clause 1. 연속형 변수 거리
연속형 변수 거리로는 유클리드 거리, 맨하튼 거리, 민코프스키 거리, 표준화 거리, 마할라노비스 거리 등이 있다.

Clause 2. 명목형 변수 거리
모든 변수가 명목형인 경우에는 개체 i 와 j 간 거리의 정의이다.
` d(i,j)=(개체 i와 j에서 다른 값을 가지는 변수의 수)/(총 변수의 수)`
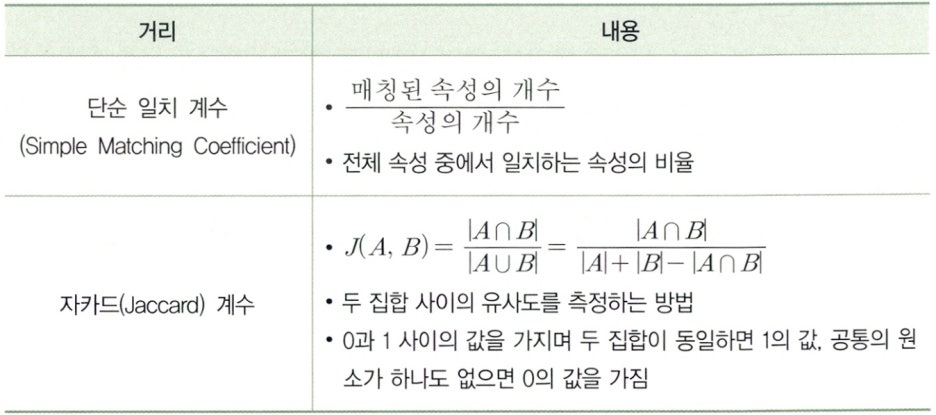
Clause 3. 순서형 자료
순위상관계수(Rank Correlation Coefficient)를 이용하여 거리르 측정한다.

Paragraph 3. 군집 분석 종류 ㅡ k-평균 군집
Subparagraph 1. k-평균 군집 개념
주어진 데이터를 k개의 군집으로 묶는 알고리즘으로 k개만큼 군집 수를 초깃값으로 지정하고, 각 개체를 가까운 초깃값에 할당하여 군집을 형성하고 각 군집의 평균을 재계산하여 초깃값을 갱신하는 과정을 반복하여 k개의 최종군집을 형성한다.
Subparagraph 2. k-평균 군집의 절차(알고리즘)
- k-평균 군집에서 군집의 수(k)는 하이퍼 파라미터로서 미리 정해 주어야 한다.
- k개의 초기 중심 값은 임의로 선택할 수 있으며 자료 중에서 임의로 선택도 가능하다.
| 단계 | 알고리즘 | 설명 |
|---|---|---|
| 1 | k개 객체 선택 | 초기 군집 중심으로 k개의 객체를 임의로 선택함 |
| 2 | 할당(Assignment) | 자료를 가장 가까운 군집 중심에 할당 |
| 3 | 중심 갱신(New Centroids) | 각 군집 내의 자료들의 평균을 계산하여 군집의 중심을 갱신 |
| 4 | 반복 | 군집 중심의 변화가 거의 없을 때(또는 최대 반복수)까지 단게 2와 단계 3을 반복 |
- k-평균 군집은 이상값에 민감하게 반응하는 단점이 존재한다.
- 단점을 보완하는 방법으로는
k-중앙값 군집을 사용하거나 이상값을 미리 제거할 수도 있다.
Paragraph 4. 군집 분석 종류 ㅡ 혼합 분포 군집
Subparagraph 1. 혼합 분포 군집(Mixture Distribution Clustering) 개념
- 혼합 분포 군집은 데이터가 k개의 모수적 모형의 가중합으로 표현되는 모집단 모형으로부터 나왔다는 가정하엣서 자료로부터 모수와 가중치를 추정하는 방법이다.
- k개의 각모형은 군집을 의미하며, 각 데이터는 추정된 k개의 모형 중 어느 모형으로부터 나왔을 확률이 높은지에 따라 군집의 분류가 이루어진다.
- M개 분포(성분)의 가중합으로 표현되는 혼합모형의 정의는 다음과 같다.

- 혼합모형의 모수를 추정하는 경우 단일 모형과는 달리 표현식이 복잡하여 미분을 통한 이론적 전개가 어렵기 때문에 최대가능도 추정을 위해 EM 알고리즘 등을 이용한다.
Subparagraph 2. EM 알고리즘
Clause 1. EM(Expectation-Maximization) 알고리즘 개념
관측되지 않은 잠재변수에 의존하는 확률모델에서 최대 가능도나 최대 사후 확률을 갖는 모수의 추정값을 찾는 반복적인 알고리즘이다.
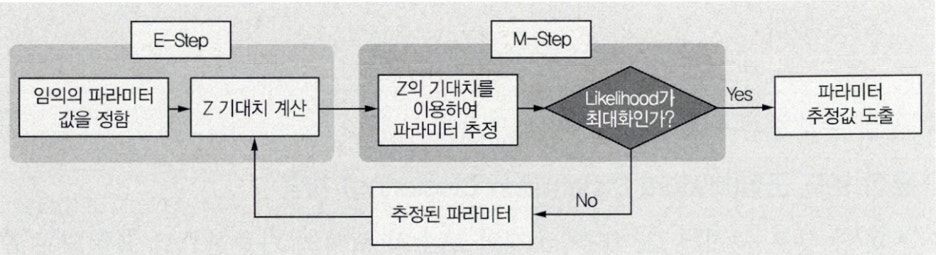
Clause 2. EM 알고리즘 진행 과정
- EM 알고리즘은 E-단계(E-step), M-단계(M-step)로 진행된다.
- E-단계는 잠재변수 Z의 기대치를 계산하고 M-단계는 잠재변수 Z의 기대치를 이용하여 파라미터를 추정한다.
- 반복을 수행하며 파라미터 추정값을 도출하며 이를
최대 가능도추정치로 사용한다.
Subparagraph 3. 혼합 분포 군집의 특징
- 확률 분포를 도입하여 군집을 수행한다.
- 군집을 몇 개의 모수로 표현할 수 있고, 서로 다른 크기의 군집을 찾을 수 있다.
- EM 알고리즘을 이용한 모수 추정에서 데이터가 커지면 수렴에 시간이 걸릴 수 있다.
- 군집의 크기가 너무 작으면 추정의 정도가 떨어지거나 어려울 수 있다.
- 이상값에 민감하므로 이상값 제거 등의 사전 조치가 필요하다.
Paragraph 5. 군집 분석 종류 ㅡ SOM
Subparagraph 1. 자기 조직화 지도(Self-Organizing Maps; SOM) 개념
- SOM은 대뇌피질과 시각피질의 학습 과정을 기반으로 모델화한 인공신경망으로 자율 학습 방법에 의한 클러스터링 방법을 적용한 알고리즘이다.
- 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화한 비지도 신경망이다.
- 형상화는 입력변수의 위치 관계를 그대로 보존한다는 특징이 있다.
- 실제 공간의 입력변수가 가까이 있으면 지도상에는 가까운 위치에 있게 된다.
Subparagraph 2. SOM 구성
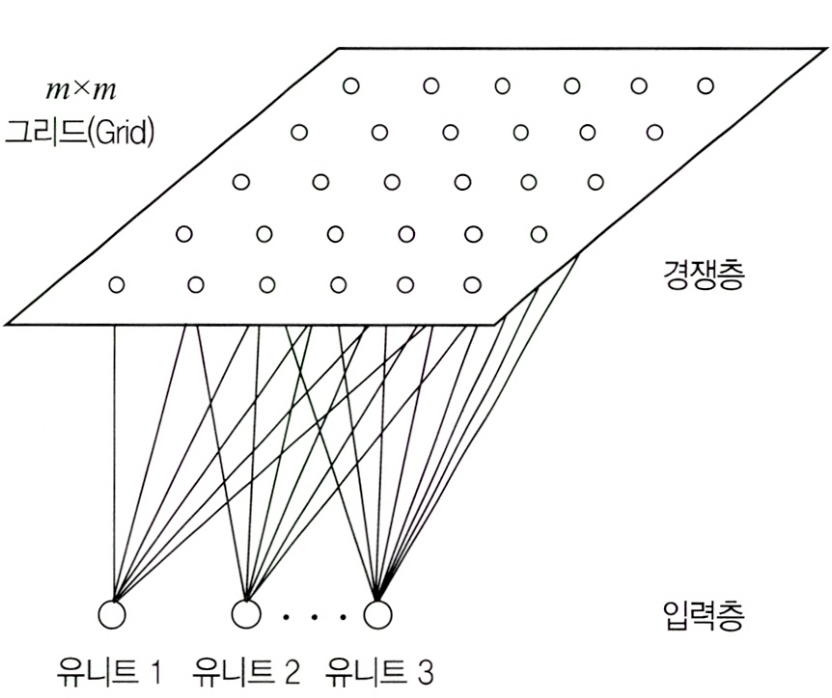
SOM은 입력층과 경쟁층으로 구성된다.
| 구성 | 내용 |
|---|---|
| 입력층 (Input Layer) |
• 입력 벡터를 받는 층으로 입력변수의 개수와 동일하게 뉴런 수가 존재함• 입력층의 자료는 학습을 통하여 경쟁층에 정렬되는데 이를 지도(Map)라고 부름 • 입력층에 있는 각각의 뉴런은 경쟁층에 있는 각각의 뉴런들과 연결되어 있으며 이때 완전 연결되어 있음 |
| 경쟁층 (Competitive Layer) |
• 2차원 격차(Grid)로 구성된 층으로 입력 벡ㄱㄱ터의 특성에 따라 벡터의 한 점으로 클러스터링되는 층 • SOM은 경쟁 학습으로 각각의ㅏ 뉴런이 입력 벡터와 얼마나 가까운가를 계산하여 연결 강도를 반복적으로 재조정하여 학습하며, 이 과정을 거치면서 연결 강도는 입력 패턴과 가장 유사한 경쟁층 뉴런이 승자가 됨 • 승자 독식 구조로 인해 경쟁층에 승자 뉴런만이 나타나며, 승자와 유사한 연결 강도를 갖는 입력 패턴이 동일한 경쟁 뉴런으로 배열됨 |
Subparagraph 3. SOM 학습 알고리즘
SOM 학습 알고리즘은 다음과 같이 구성되어 있다.
| 순서 | 단계 | 내용 |
|---|---|---|
| 1 | 초기화 | SOM 맵의 노드에 대한 연결 강도를 초기화 |
| 2 | 입력 벡터 | 입력 벡터를 제시 |
| 3 | 유사도 계산 | 유클리드 거리를 사용하여 입력 벡터와 프로토타입 벡터 사이의 유사도(Similarity)를 계산 |
| 4 | 프로토타입 벡터 탐색 | 입력 벡터와 가장 거리가 짧은 프로토타입 벡터(BMU)를 탐색 |
| 5 | 강도 재조정 | BMU와 그 이웃들의 연결 강도를 재조정 |
| 6 | 반복 | 단계 2로 가서 반복 |